LEARNING FROM INCIDENTS
Andrew Hatch
@hatchman76

https://www.sli.do/
55952
Business orgin
Based in Melbourne
Mostly in AWS
Ship a lot
Seek today...
1997

#1 Jobs Site


~200

1000+
Stuff breaks...
...we should expect it to
How we used to do incidents
When we tried to fix things
Where our thinking did not support the complex system we were building
Changing the way we think about systems and people
Building a more supportive incident management process
How we need to think about complex systems in the future
Content


5 x WHY? =
RCA!!




teams worked in islands
operations hated deployments
incidents had some monitoring but many times it would be the customers telling us
>About 6 years ago








Knowledge existed almost exclusively in operations and customer support teams
The rest of Seek was largely oblivious, which was more or less how poeple expected it to be
When it came to incident learning

But life is much better now
No more silos, we ship lots of code, we diversify our software
But doing this exposed a critical flaw in how we handle and anticipate failure
Because our software systems evolved to a much more distributed complexity model
In the year 2019
DevOps as a Culture




Our environment became much more complex....
...our ability to adapt and learn from failure did not keep up
But our system is getting complex. Teams produce lots of API's
Those API's have dependencies


Knowledge of incidents is no longer siloed
Handling and anticipation is localised
Systems change frequently, not all performance is expected or predictable.
Handling incidents starts to change

Localised
Distributed
Complexity hasn't gone away....
...we've just moved it
Incident profiles have started to change
And as profiles chnaged it exposed a lack of skill in managing unpredictable and unforseen events
The Black Swan event was about to happen
Increased integration points
+ tight & loose couplings
+ localised decision making
= Emergent Behaviours

January 2017
10K Customers
18 hours of outage

A routine update of Windows DNS caused catastrophic failure in our DataCentre and AWS
It exposed some implemntations of Linux inability to cahce DNS records, sending network traffic flooding from retires and failures
The failure was so widepsread it was impossible to know where all the issues were
It also highlighted how little teams that had been put on support roles knew how to diagnose DNS related issues
one day in May 2017...

DNS

12 hours of continuous outage!


Immediately looked at getting more information around incidents
Management had to be seen to be in control of failure
Because failure is often perceived as a lack of control
Safety Incident Management 1.0


Incident Post-mortems
Focused heavily on the root cause

Encouraged to use 5 whys


"How could you not have noticed that?"
"But isn't that the way it should work?""
Hindsight bias
Action items were created. But they were very localised and specific. Underlying systemic problems were not always addressed
Large focus on people failure, conversations were pre-loaded to fail
Safer systems were assumed to attained only from an decrese in incidents - the ones that were known.
Safety can be defined as a state where as few things go wrong as possible - theories developed in the 1960's and 1980's.
Generally systems were simpler, able to be decomposed And the functions of the systems did so in a bimodal manner
Reporting in this way became a process of pushing accountability up not a responsibility down
Weekly Incident Review...

Localised

"we don't want this...
...to be too comfortable"

IN

OUT

Reliable?
Things still keep going wrong. Even as recently as last month
This is the flipside to DevOps all the Things. Distributing ownership means distributing complexity and variability at the edge
If teams are not guided through the transition nor appreciate the complexities of operational production systems then why are we treating them this way?
...not really


WHy aren't we seeing the system for what it has become. A complex socio-technical system that is in a state of constant variation and change
Why do we spend so much time on what is failing, and not what is going well create an environment that enables us to just do more of that?
Why have we been conditioned to think this way?
What about...




Management of work
People are the unpredictable parts of the system
variance and local adaptation must be neutralised
Management should enforce rules and workers should obey
All functions and associated training are defined in intimate detail, people only act as directed

Frederick Winslow Taylor
The Principles of Scientific Management (1911)
=
"unpredictable"
"inefficient"
"untrustworthy"

WORK-AS-IMAGINED = WORK-AS-DONE



rooted in linear thinking, which is understandable due to the mass industrilaisation of the 20th century.
Mechanisation of animals from the late 18th century reaching it's zenith in the early 20th. Mechanisation of thought, electrons replacing gears and cogs
>Incidents followed this pattern. Problems are thought of a chain of events, needing isolation down
More of than not this is the human, the unpredictable, flawed component of the system
Breakdown follows reductionism principles
Linear Thinking
Chain of events
Isolate down to a single origin of failure
1:1 Cause and Effect
Human Error!
1950's
Five Whys
Root Cause Analysis
60 years later...
Modern complexity
RCA and 5 whys may work well for early to mid 20th century manfacturing
But there is a lot greater complexity in the systems we build now
At Seek our AWS Footprint and the number of teams we have number
We may deploy like pipelines but our production systems resemble a decision tree - not an assembly line
1500+

1000+

200+

4600+
~200

+2K
30+
API or Event driven
Loose or tightly coupled
Change can be unpredictable
Not all integrations are known!
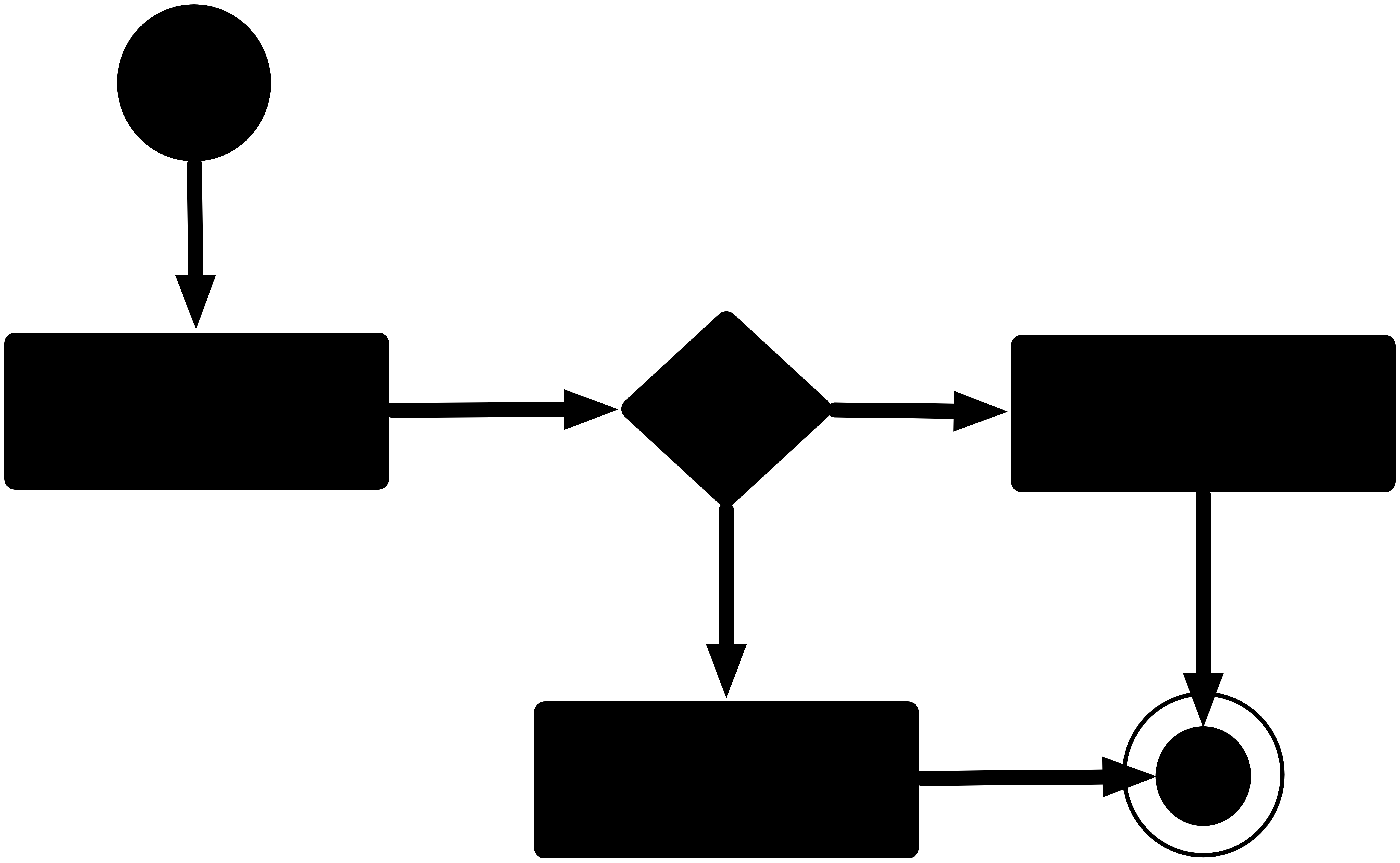
RCA fails complex system learnings
here is a simple example of why RCA fails in this complex environment and inhibits, learning andcreativity
Root Cause Analysis (RCA), a common practice throughout the software industry, does not provide any value in preventing future incidents in complex software systems. Instead, it reinforces hierarchical structures that confer blame, and this inhibits learning, creativity, and psychological safety.
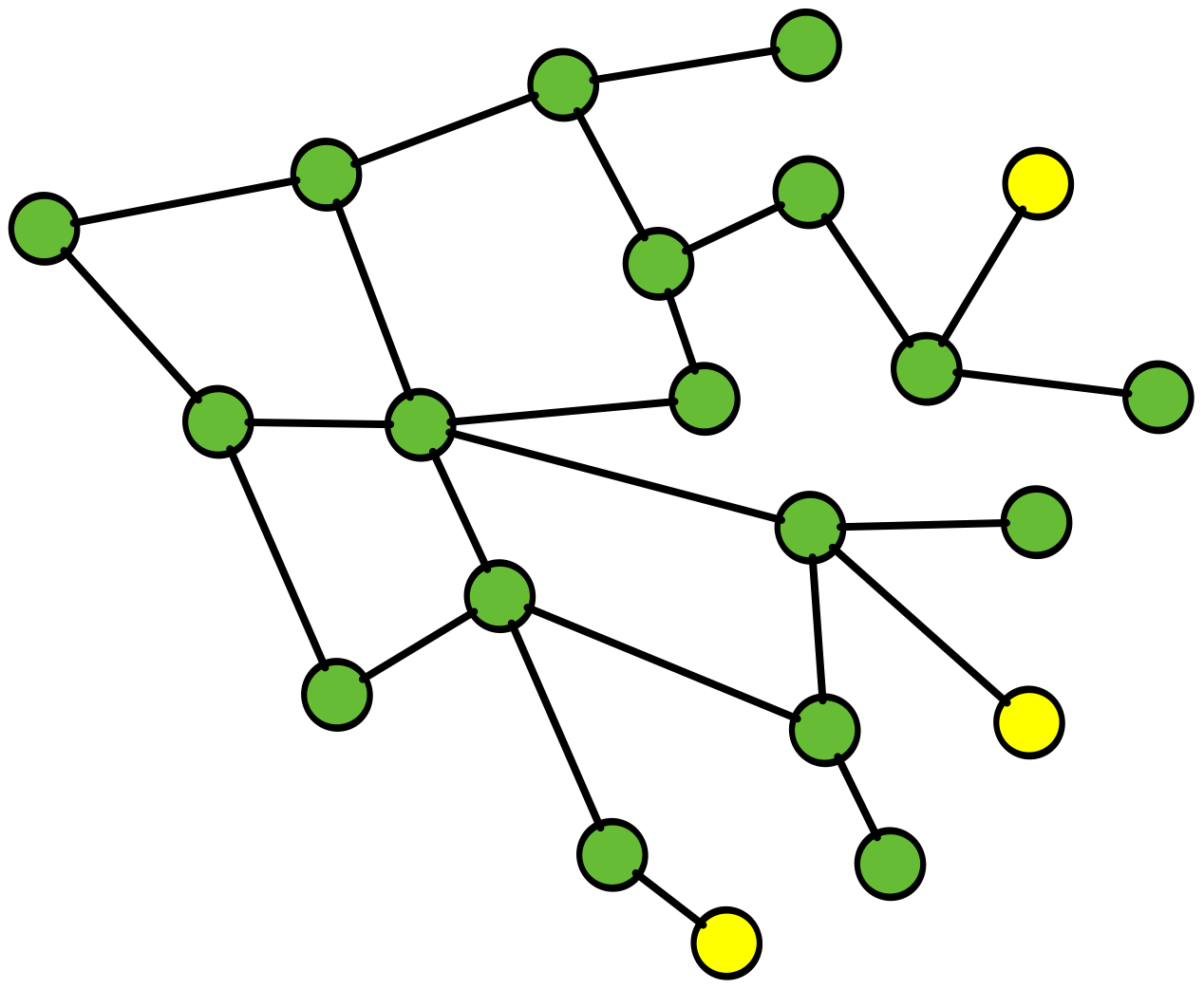
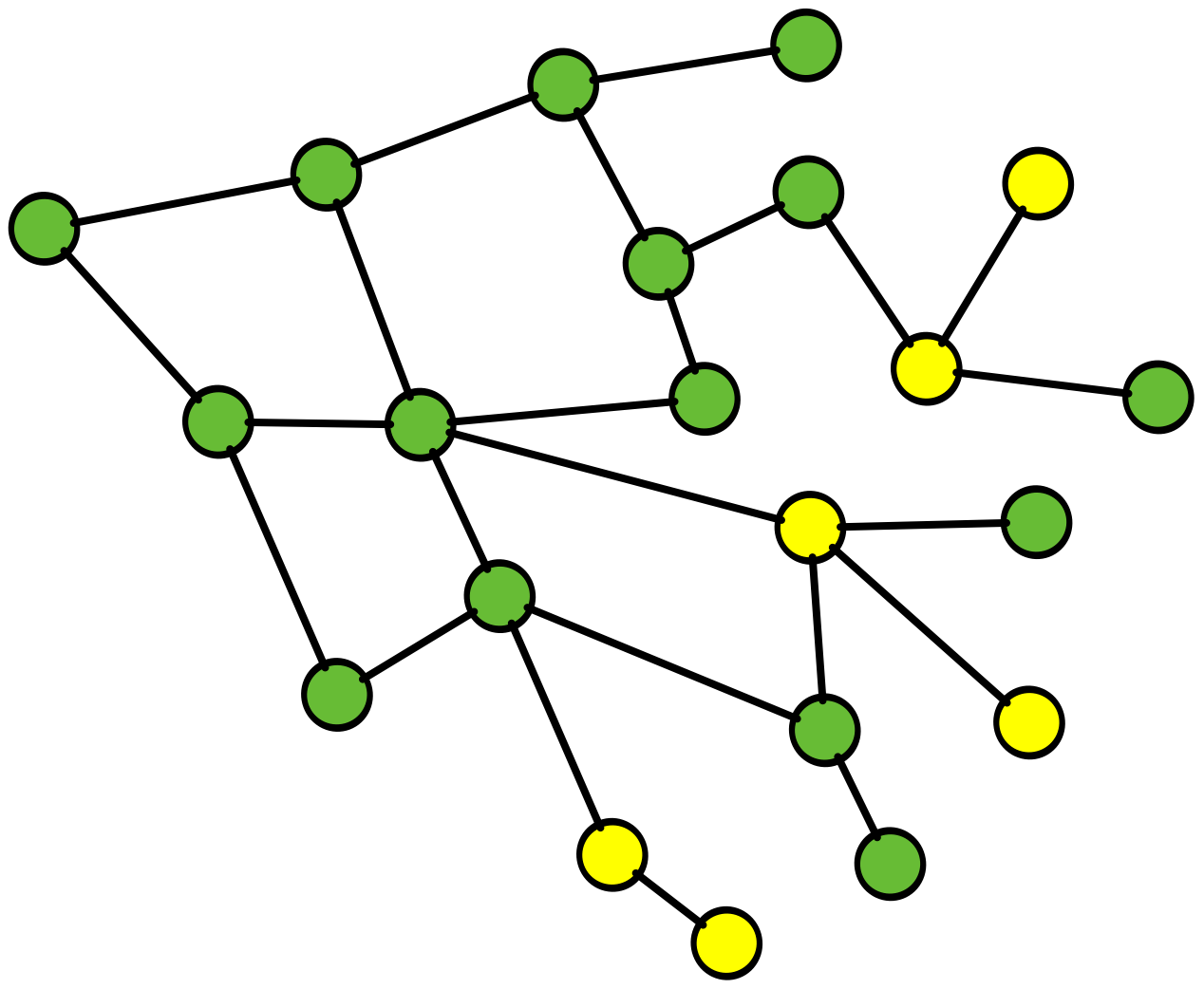
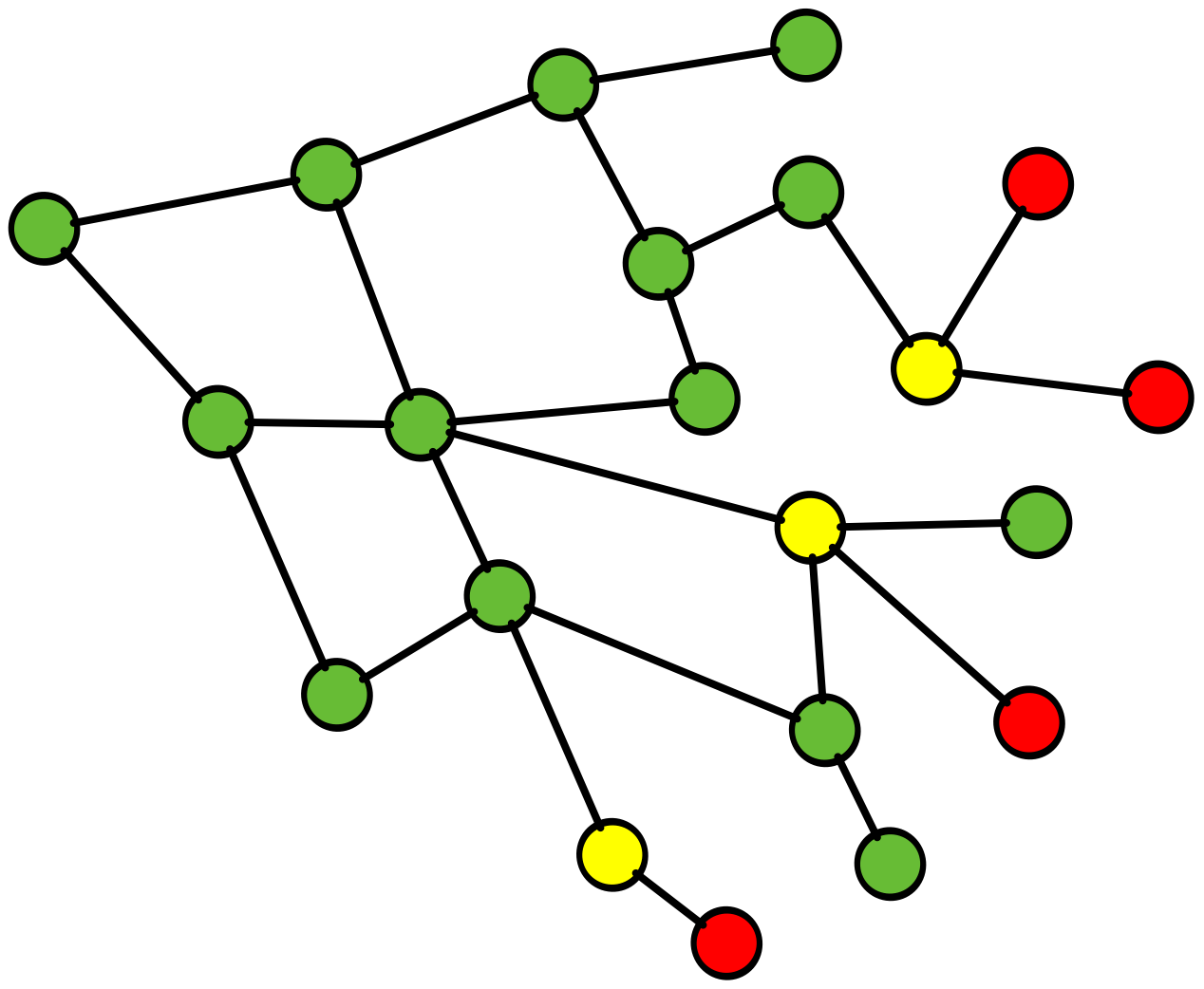
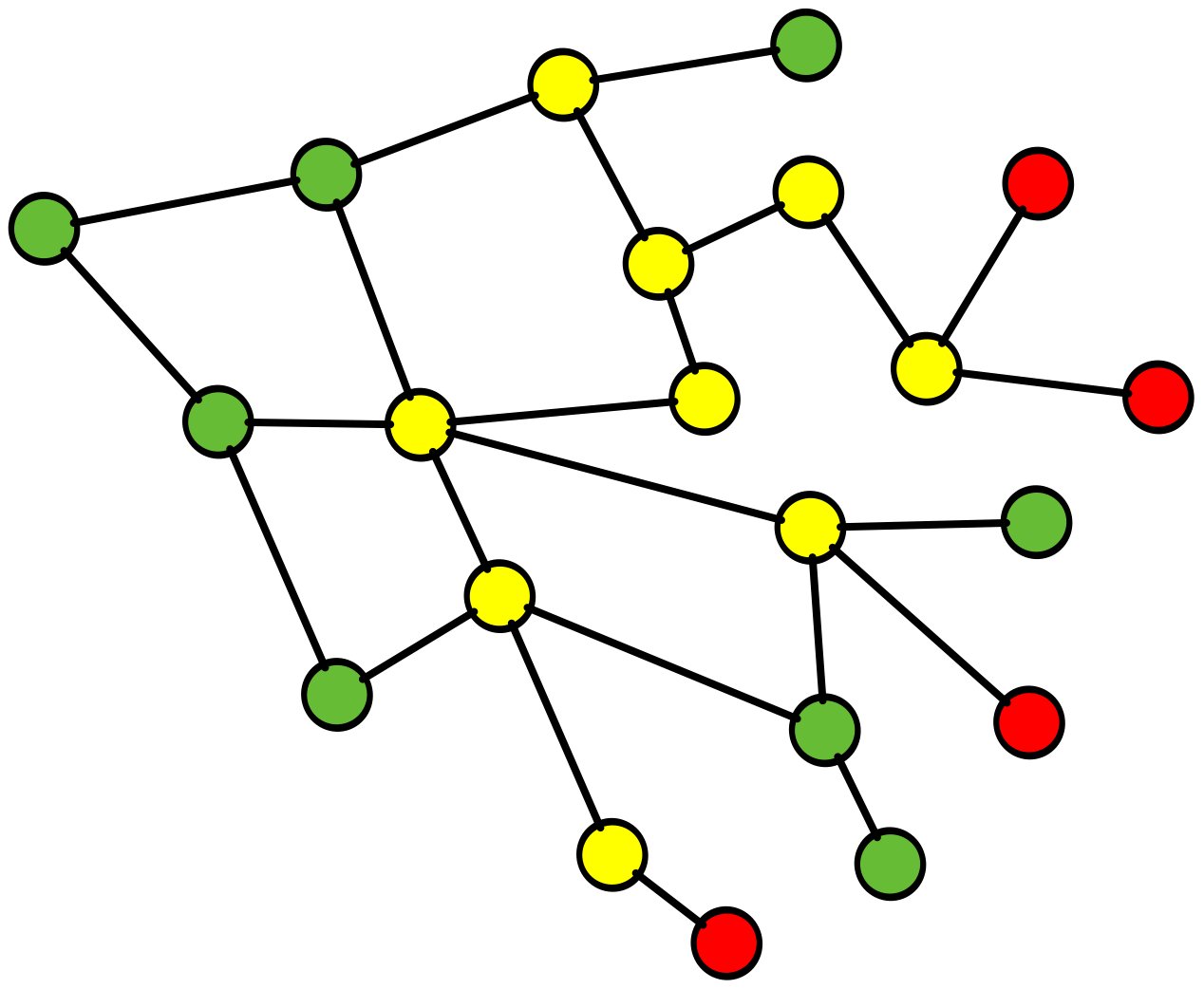
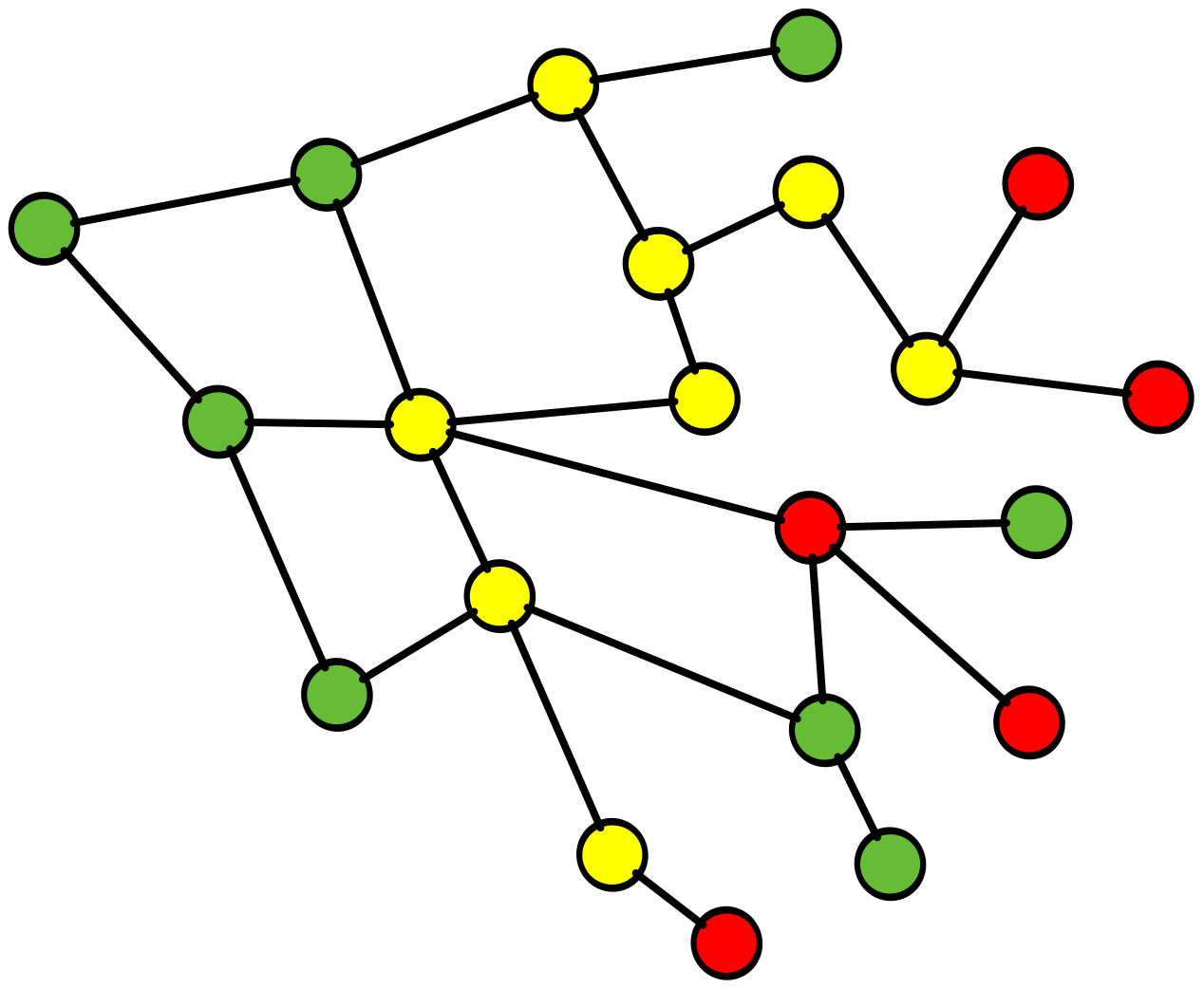
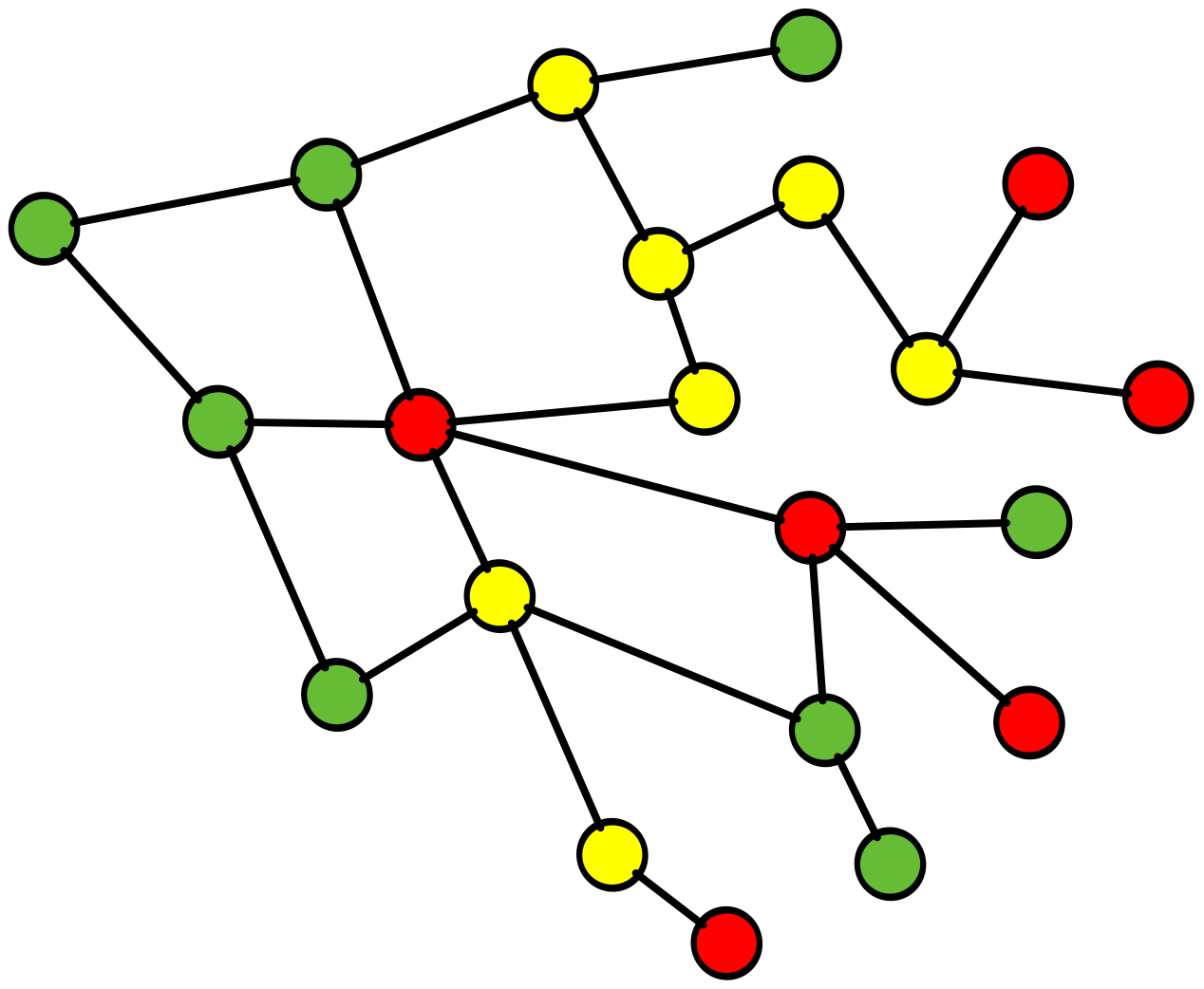
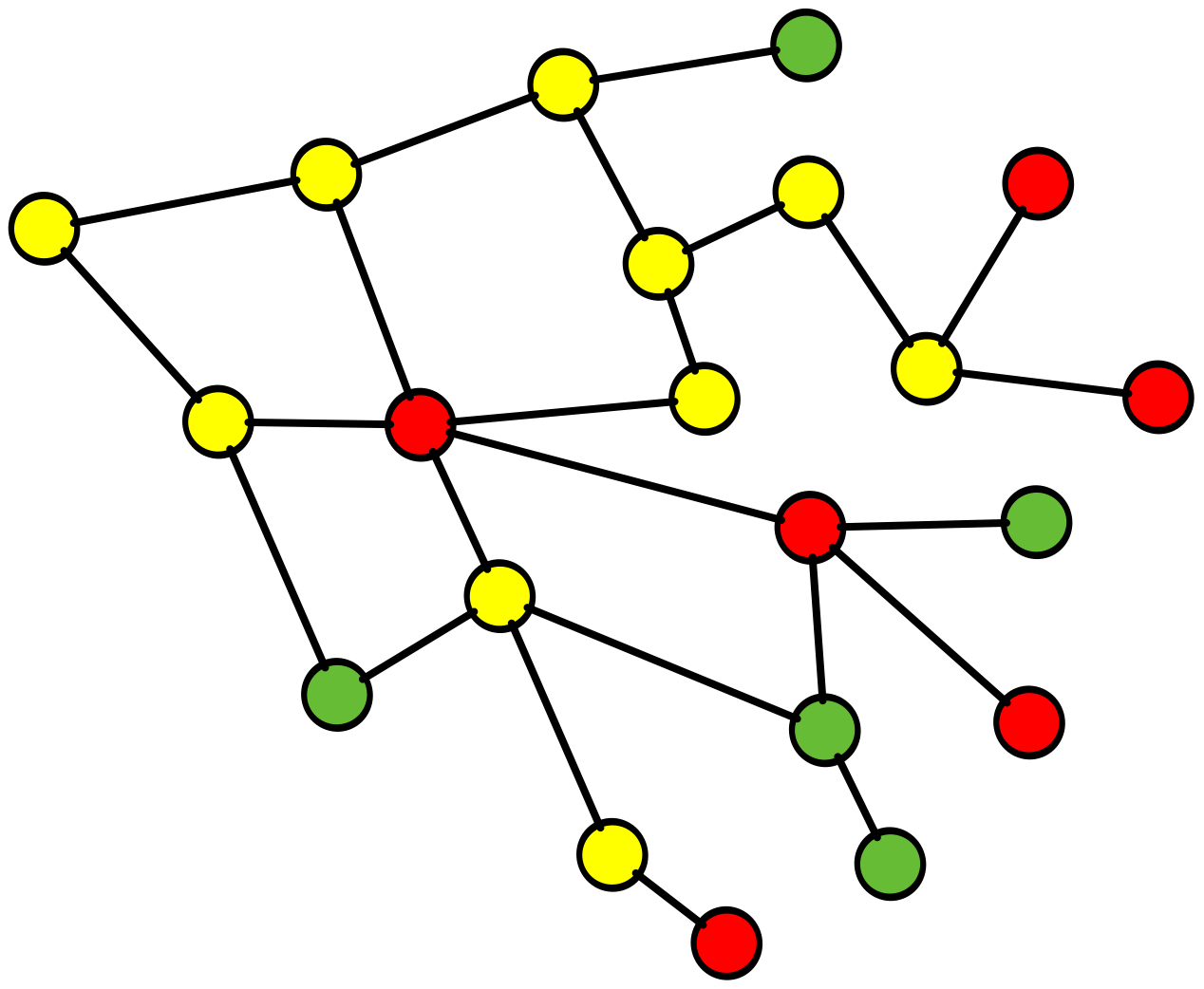
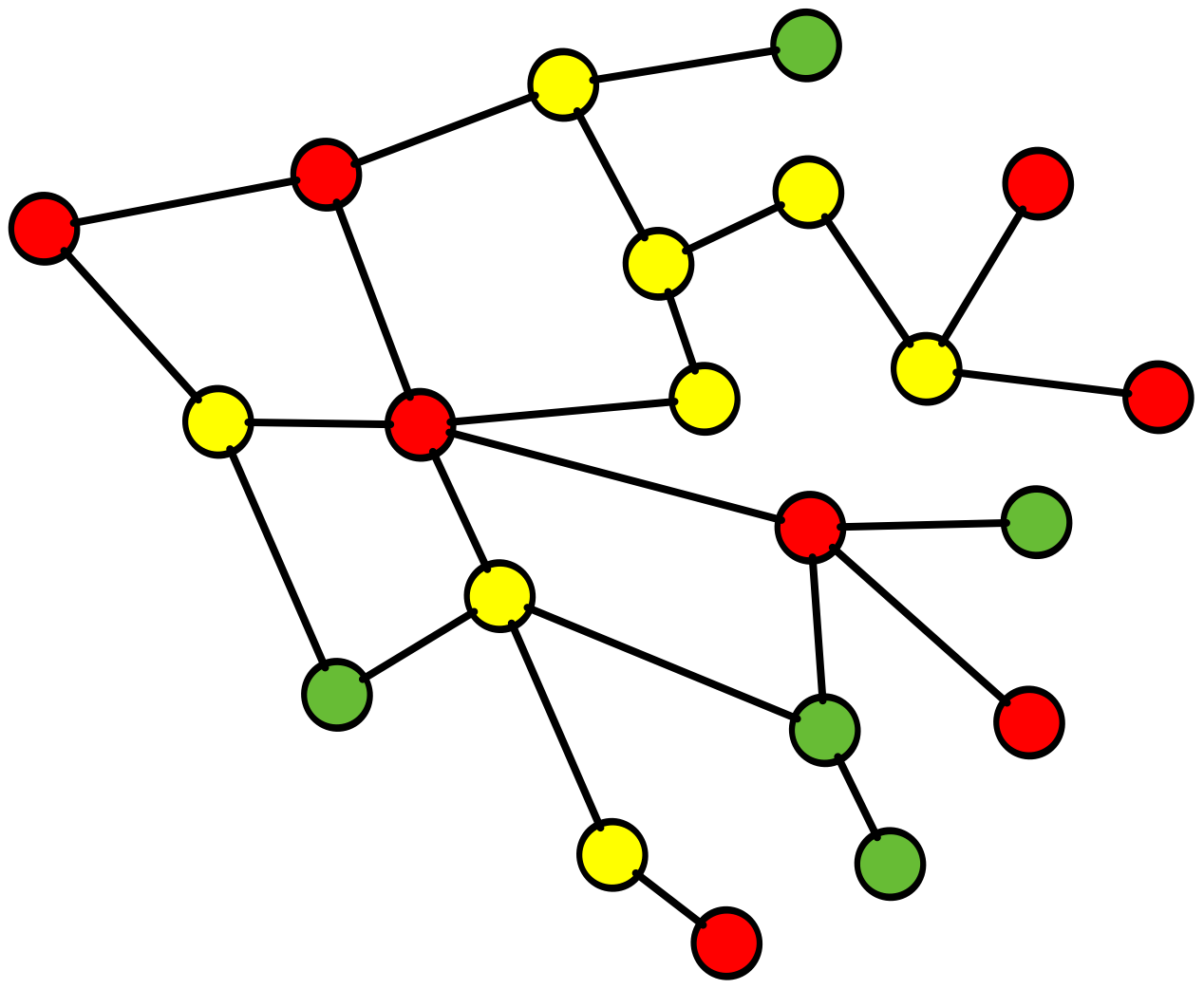
ROOT CAUSE!
???
???
???
What are we observing?
Localised management as complexity grows
Evolve independently, do not resemble assembly lines

Expensive, slow, trivialises failure
Incidents are not just about knowing what pressure the system experience
we need to understand the pressure that people go through as well
Environment like before, during and after the incident
Westrum in here about shoot, bury or embrace
What do the teams do well, how do we do more of that
Improving incident learning

Deadline pressure
Fatigue.
Communications, etc..
Anxiety
Stress
Happy?



Pathological
Bureaucratic
Generative
The Post-Mortem



Contributing factors
Timelines
Contributing factors

Scribe
Facilitator
Patterns
Themes
Focus areas
Support & assistance
teams think more about balancing reliability with delivery speed
Realising value



Edge Networking
Logging
Build Automation

Greater understanding of what our system really is. Complex, sometimes unpredictable.
Things beyond our control and we need to be cool with that
Improved understanding
Complexity does not decrease
Feedback loops can sometimes be unintended
Emergent incidents are a reality
Are the flexible and adaptable parts of the system
We have to trust and support them
=
And this will lead us to...
Resilience Engineering
It is a Field and a Community
It's not a tool or a product.
It is multi-disciplinary, it crosses multiple industries, has origins dating back several decades but has become more of a "thing" in the past 15 years. In other words there is a lot of academic material, it is highly opinionated and that is great because it provokes great discussion
resiliencepapers.club
A resilient system is able effectively to adjust its functioning prior to, during, or following changes and disturbances, so that it can continue to perform as required after a disruption or a major mishap, and in the presence of continuous stresses.
Sustained Adaptive Capacity
It is both a field and a community, with origins in multiple disciplines
It is what your organisation does. Not what it has.
Understanding Resiliency
Not a tool, not a prescribed methodology or process, or management consulting SOW
It is about seeing people and systems together, their interactiosn and feedback loops, complexity as emergence
Natural world. Gum tree, cope with fire, flood, drought. But not emergent threats such as extremem climate change, or a chainsaw!
Bones as an archetype of resilience. We've known how to knit bones for thousands of years but only in the last 100 have we perfected surgery and medical treatments to repair them more reliably
We can't afford to wait 100,000 years though, as systems get more complex we have to adapt and learn faster
Then leading change by focusing on what is done well, further driving a learning culture
When done well it will enable greater adaptation to market forces and challenges
I don;t profess to be an expert: Here is one of the best places to start reading: https://github.com/lorin/resilience-engineering

The natural world has plenty of examples

Australian Gum Tree


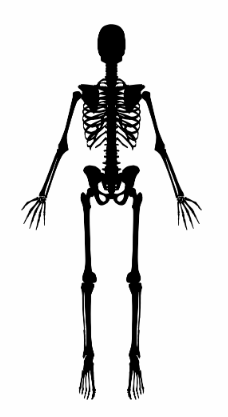
Osteoclasts
Osteoblasts
Osteocytes

Unforseen event!!!
But not emergent threats such as extremem climate change, or a chainsaw!
We can't afford to wait 100,000 years though, as systems get more complex we have to adapt and learn faster
Then leading change by focusing on what is done well, further driving a learning culture
When done well it will enable greater adaptation to market forces and challenges
I don;t profess to be an expert: Here is one of the best places to start reading: https://github.com/lorin/resilience-engineering
You can't wait for resilience to evolve naturally.
It must become an on-going practice
Create conditions and environments where teams can sustain adaptive capacity - wherever the work-is-done
Learn from incidents as much as possible
They are normal by-products of building complex systems.
Use them.
Seek to understand the intimate interactions between people and technology.
Don't isolate them
as
separate challenges
Learn from Safety-2 thinking. Focus and promote what you do well. Sustain and grow the learning culture
Thank you
https://lfi-yow.hatchman76.com
@hatchman76